

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 92731大模型×文本水印:清华、港
- 91612一文读懂如何基于 GenA
- 912132024 年,3 项技术将
- 90924AI在工业物联网(IIoT
- 90865人工智能和机器学习在物联网
- 90866利用人工智能增强网络安全防
- 90827GPT-4准确率最高飙升6
- 90618一句话让小姐姐为我换了N套
- 90579AI时代来了,专业摄影师会
- 9052102024年人工智能与数字孪
推荐阅读
- 01-241技术趋势:2024年的热点是什么
- 01-252网络安全在自动驾驶汽车中的作用
- 01-253OpenAI创始人想打造全球芯片
- 01-264强化学习和世界模型中的因果推断
- 01-265Mamba论文为什么没被ICLR
- 01-296让知识图谱成为大模型的伴侣
- 01-297从20亿数据中学习物理世界,基于
- 01-298谷歌云与Hugging Face
- 01-299人工智能和机器学习在物联网中的作
- 01-2910无需人工标注!LLM加持文本嵌入
NeurIPS 2023精选回顾:大模型最火,清华ToT思维树上榜
近日,作为美国前十的科技博客,Latent Space对于刚刚过去的NeurIPS 2023大会进行了精选回顾总结。
在NeurIPS会议总共接受的3586篇论文之中,除去6篇获奖论文,其他论文也同样优秀和具有潜力,甚至有可能预示着下一个AI领域的新突破。
那就让我们来一起看看吧!

论文题目:QLoRA: Efficient Finetuning of Quantized LLMs

论文地址:https://openreview.net/pdf?id=OUIFPHEgJU
这篇论文提出了QLoRA,这是LoRA的一种更省内存但速度较慢的版本,它使用了几种优化技巧来节省内存。
总体而言,QLoRA使得在对大型语言模型进行微调时可以使用更少的GPU内存。
他们训练了一个新模型,Guanaco,仅在单个GPU上进行了为期24小时的微调,并在Vicuna基准测试中表现优于先前的模型。
与此同时,研究人员还开发了其他方法,如4-bit LoRA量化,其效果相似。

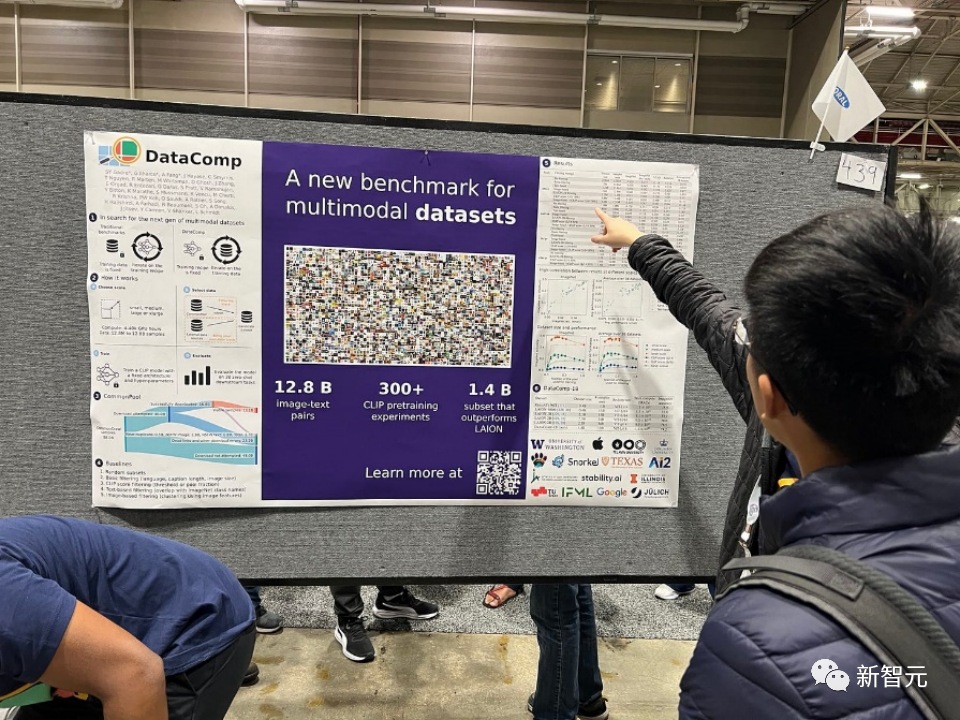
论文题目:DataComp: In search of the next generation of multimodal datasets

论文地址:https://openreview.net/pdf?id=dVaWCDMBof
多模态数据集在最近的突破中扮演着关键角色,如CLIP、Stable Diffusion和GPT-4,但与模型架构或训练算法相比,它们的设计并没有得到同等的研究关注。
为了解决这一机器学习生态系统中的不足,研究人员引入了DataComp,这是一个围绕Common Crawl的新候选池中的128亿个图文对进行数据集实验的测试平台。
使用者可以通过DataComp进行实验,设计新的过滤技术或精心策划新的数据源,并通过运行标准化的CLIP训练代码,以及在38个下游测试集上测试生成的模型,来评估他们的新数据集。
结果显示,最佳基准DataComp-1B,允许从头开始训练一个CLIP ViT-L/14模型,其在ImageNet上的零样本准确度达到了79.2%,比OpenAI的CLIP ViT-L/14模型高出3.7个百分点,以此证明DataComp工作流程可以产生更好的训练集。
论文题目:Visual Instruction Tuning

论文地址:https://arxiv.org/pdf/2304.08485v1.pdf
在这篇论文中,研究人员提出了首次尝试使用仅依赖语言的GPT-4生成多模态语言-图像指令跟随数据的方法。
通过在这种生成的数据上进行指令调整,引入了LLaVA:Large Language and Vision Assistant,这是一个端到端训练的大型多模态模型,连接了一个视觉编码器和LLM,用于通用的视觉和语言理解。
早期实验证明LLaVA展示了令人印象深刻的多模态聊天能力,有时展现出多模态GPT-4在未见过的图像/指令上的行为,并在合成的多模态指令跟随数据集上与GPT-4相比取得了85.1%的相对分数。
在对科学问答进行微调时,LLaVA和GPT-4的协同作用实现了92.53%的新的最先进准确性。

论文题目:Tree of Thoughts: Deliberate Problem Solving with Large Language Models

论文地址:https://arxiv.org/pdf/2305.10601.pdf
语言模型越来越多地被用于广泛的任务中进行一般性问题解决,但在推理过程中仍受限于标记级别、从左到右的决策过程。这意味着它们在需要探索、战略前瞻或初始决策起关键作用的任务中可能表现不佳。
为了克服这些挑战,研究人员引入了一种新的语言模型推理框架,Tree of Thoughts(ToT),它在促使语言模型方面推广了流行的Chain of Thought方法,并允许在一致的文本单元(思想)上进行探索,这些单元作为解决问题的中间步骤。
ToT使语言模型能够通过考虑多条不同的推理路径和自我评估选择来做出刻意的决策,以决定下一步行动,并在必要时展望或回溯以做出全局性的选择。
实验证明,ToT显著提高了语言模型在需要非平凡规划或搜索的三个新任务上的问题解决能力:24点游戏、创意写作和迷你填字游戏。例如,在24点游戏中,虽然使用Chain of Thought提示的GPT-4只解决了4%的任务,但ToT实现了74%的成功率。

论文题目:Toolformer: Language Models Can Teach Themselves to Use Tools

论文地址:https://arxiv.org/pdf/2302.04761.pdf
语言模型表现出在从少量示例或文本指令中解决新任务方面的显著能力,尤其是在大规模情境下。然而,令人矛盾的是,它们在基本功能方面(如算术或事实查找),相较于更简单且规模较小的专门模型,却表现出困难。
在这篇论文中,研究人员展示了语言模型可以通过简单的API自学使用外部工具,并实现两者的最佳结合。
他们引入了Toolformer,这个模型经过训练能够决定调用哪些API、何时调用它们、传递什么参数以及如何最佳地将结果合并到未来的token预测中。
这是以自监督的方式完成的,每个API只需要少量演示即可。他们整合了各种工具,包括计算器、问答系统、搜索引擎、翻译系统和日历等。
Toolformer在与更大模型竞争的时候,在各种下游任务中取得了明显改善的零样本性能,而不会牺牲其核心语言建模能力。
论文题目:Voyager: An Open-Ended Embodied Agent with Large Language Models

论文地址:https://arxiv.org/pdf/2305.16291.pdf
该论文介绍了Voyager,这是第一个由大型语言模型(LLM)驱动的,可以在Minecraft中连续探索世界、获取多样化技能并进行独立发现的learning agent。
Voyager包含三个关键组成部分:
自动课程,旨在最大程度地推动探索,
不断增长的可执行代码技能库,用于存储和检索复杂行为,
新的迭代提示机制,整合了环境反馈、执行错误和自我验证以改进程序。
Voyager通过黑盒查询与GPT-4进行交互,避免了对模型参数进行微调的需求。
根据实证研究,Voyager展现出强大的环境上下文中的终身学习能力,并在玩Minecraft方面表现出卓越的熟练度。
它获得了比先前技术水平高出3.3倍的独特物品,行进距离更长2.3倍,并且解锁关键技术树里程碑的速度比先前技术水平快15.3倍。
不过,虽然Voyager能够在新的Minecraft世界中利用学到的技能库从零开始解决新颖任务,但其他技术则难以泛化。

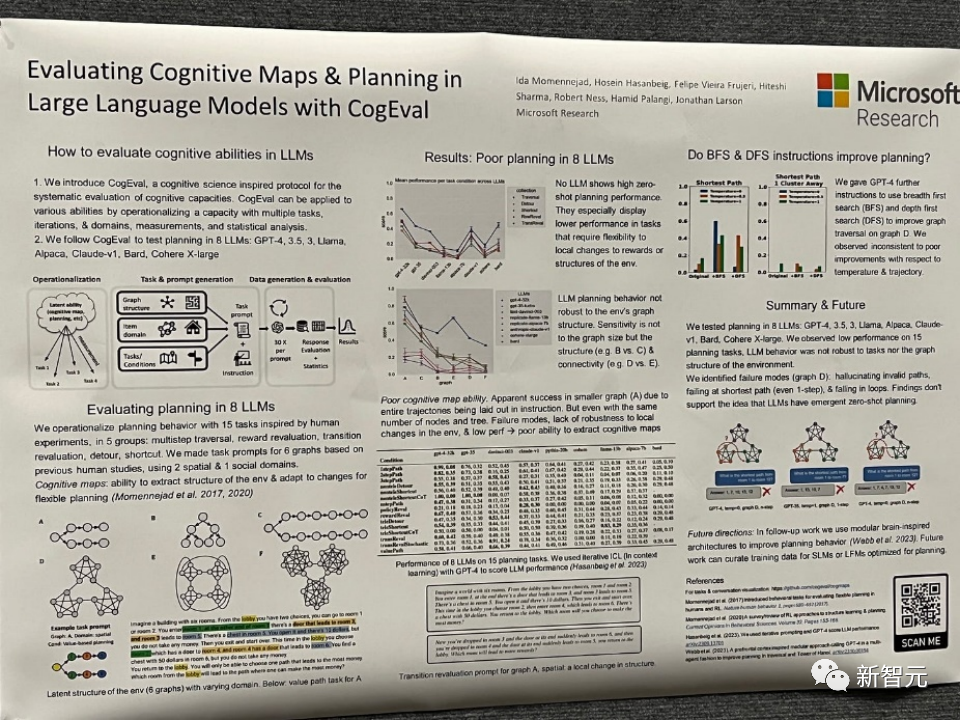
论文题目:Evaluating Cognitive Maps and Planning in Large Language Models with CogEval

论文地址:https://openreview.net/pdf?id=VtkGvGcGe3
该论文首先提出了CogEval,这是一个受认知科学启发的系统评估大型语言模型认知能力的协议。
其次,论文使用CogEval系统评估了八个LLMs(OpenAI GPT-4、GPT-3.5-turbo-175B、davinci-003-175B、Google Bard、Cohere-xlarge-52.4B、Anthropic Claude-1-52B、LLaMA-13B和Alpaca-7B)的认知地图和规划能力。任务提示基于人类实验,并且不在LLM训练集中存在。
研究发现,虽然LLMs在一些结构较简单的规划任务中显示出明显的能力,但一旦任务变得复杂,LLMs就会陷入盲区,包括对无效轨迹的幻觉和陷入循环。
这些发现不支持LLMs具有即插即用的规划能力的观点。可能是因为LLMs不理解规划问题背后的潜在关系结构,即认知地图,并在根据基础结构展开目标导向轨迹时出现问题。
论文题目:Mamba: Linear-Time Sequence Modeling with Selective State Spaces

论文地址:https://openreview.net/pdf?id=AL1fq05o7H
作者指出了目前许多次线性时间架构,如线性注意力、门控卷积和循环模型,以及结构化状态空间模型(SSMs),旨在解决Transformer在处理长序列时的计算效率低下问题。然而,这些模型在重要的语言等领域上并没有像注意力模型那样表现出色。作者认为这些
型的一个关键弱点是它们无法进行基于内容的推理,并进行了一些改进。
首先,简单地让 SSM 参数作为输入的函数,可以解决其离散模态的弱点,允许模型根据当前标记选择性地沿序列长度维度传播或忘记信息。
其次,尽管这种变化阻止了高效卷积的使用,但作者在循环模式下设计了一种硬件感知的并行算法。将这些选择性 SSM 集成到简化的端到端神经网络架构中,无需注意力机制,甚至不需要 MLP 模块 (Mamba)。
Mamba在推理速度上表现出色(比Transformers高5倍),并且在序列长度上呈线性缩放,在真实数据上的性能提高了,达到了百万长度序列。
作为一种通用的序列模型骨干,Mamba在语言、音频和基因组学等多个领域取得了最先进的性能。在语言建模方面,Mamba-1.4B模型在预训练和下游评估中均优于相同大小的Transformers模型,与其两倍大小的Transformers模型相匹敌。

虽然这些论文在2023年没有获得奖项,但比如Mamba,作为一种能够革新语言模型架构的技术模型,评估其影响还为时过早。
明年NeurIPS会如何走向,2024的人工智能和神经信息系统领域又会如何发展,虽然目前众说纷纭,但又有谁能打包票呢?让我们拭目以待。
关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP