

合作机构:阿里云 / 腾讯云 / 亚马逊云 / DreamHost / NameSilo / INWX / GODADDY / 百度统计
资讯热度排行榜
- 203581云服务器有哪些维护技巧,你
- 198732网站打开速度慢的代价:超过
- 190803域名备案需要准备什么?
- 172194云服务器小常识
- 167625云服务器和云盘的区别
- 165596个人如何注册域名?
- 165147大数据和云计算的发展前景如
- 103148MySQL体系架构
- 86819河南服务器托管哪家好?
- 509110推荐一些真正便宜的企业云服
推荐阅读
- 01-071什么是Helm?它是如何提升云原
- 01-1022024年云计算的四大趋势
- 01-123到2026年,边缘计算支出将达到
- 01-174混合云的力量实际上意味着什么?
- 01-195白话Kubernetes网络
- 01-226从集中式到分布式:云应用管理的未
- 01-237大技术时代的网络转型
- 01-248企业转型:虚拟化对云计算的影响
- 01-259到2028年,云计算市场将达到1
- 01-2510云应用管理的未来:分布式云环境
解密Kafka主题的分区策略:提升实时数据处理的关键

Kafka几乎是当今时代背景下数据管道的首选,无论你是做后端开发、还是大数据开发,对它可能都不陌生。开源软件Kafka的应用越来越广泛。
面对Kafka的普及和学习热潮,哪吒想分享一下自己多年的开发经验,带领读者比较轻松地掌握Kafka的相关知识。
今天系统的说一下Kafka的分区策略,实现步步为营,逐个击破,拿下Kafka。
一、Kafka主题的分区策略概述
理解Kafka主题的分区策略对于构建高性能的消息传递系统至关重要。深入探讨Kafka分区策略的重要性以及如何在分布式消息传递中使用它。
1、什么是Kafka主题的分区策略?
Kafka是一个分布式消息传递系统,用于实现高吞吐量的数据流。消息传递系统的核心是主题(Topics),而这些主题可以包含多个分区(Partitions)。
分区是Kafka的基本并行处理单位,允许数据并发处理。
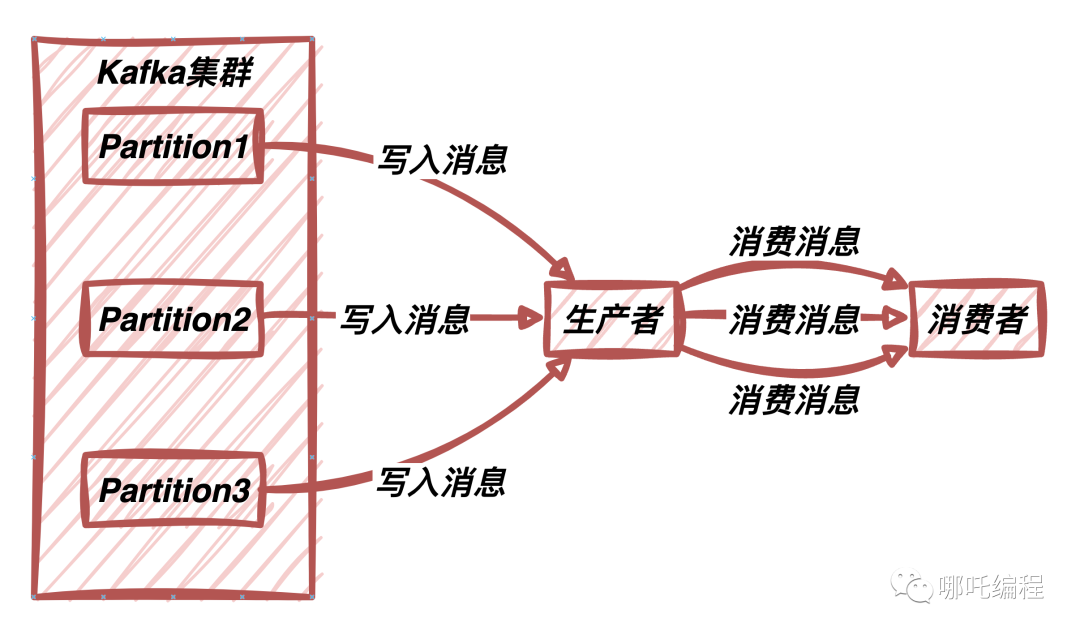
分区策略定义了消息在主题中如何分配到不同的分区。它决定了消息将被写入哪个分区,以及在消费时如何从不同分区读取消息。
分区策略是Kafka的关键组成部分,直接影响到Kafka集群的性能和数据的顺序性。
2、为什么分区策略重要?
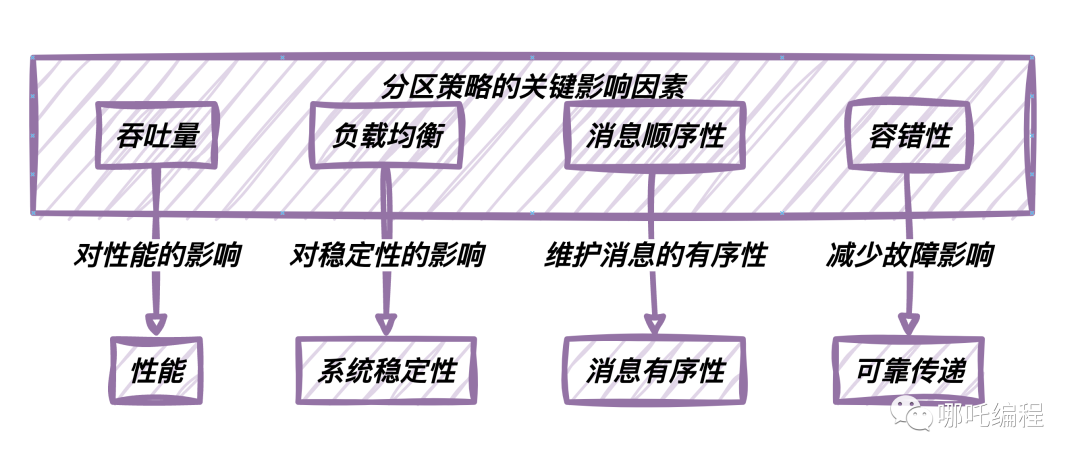
分区策略的选择对Kafka系统的性能、伸缩性和容错性产生深远影响。
以下是一些分区策略的关键影响因素:
- 吞吐量:合理的分区策略可以提高Kafka集群的吞吐量。它允许消息并行处理,提高了数据传递的效率。
- 负载均衡:分区策略有助于均衡Kafka集群中各个分区的负载。均衡的分区分布意味着没有过载的分区,从而提高了系统的稳定性。
- 顺序性:某些应用程序需要保持消息的顺序性,因此选择正确的分区策略对于维护消息的有序性至关重要。
- 容错性:合适的分区策略可以减少故障对系统的影响。在节点故障时,分区策略可以确保消息的可靠传递。
二、Kafka默认分区策略
1、Round-Robin分区策略
Kafka默认的分区策略是Round-Robin。这意味着当生产者将消息发送到主题时,Kafka会循环选择每个分区,以便均匀分布消息。
Round-Robin策略的工作原理如下:
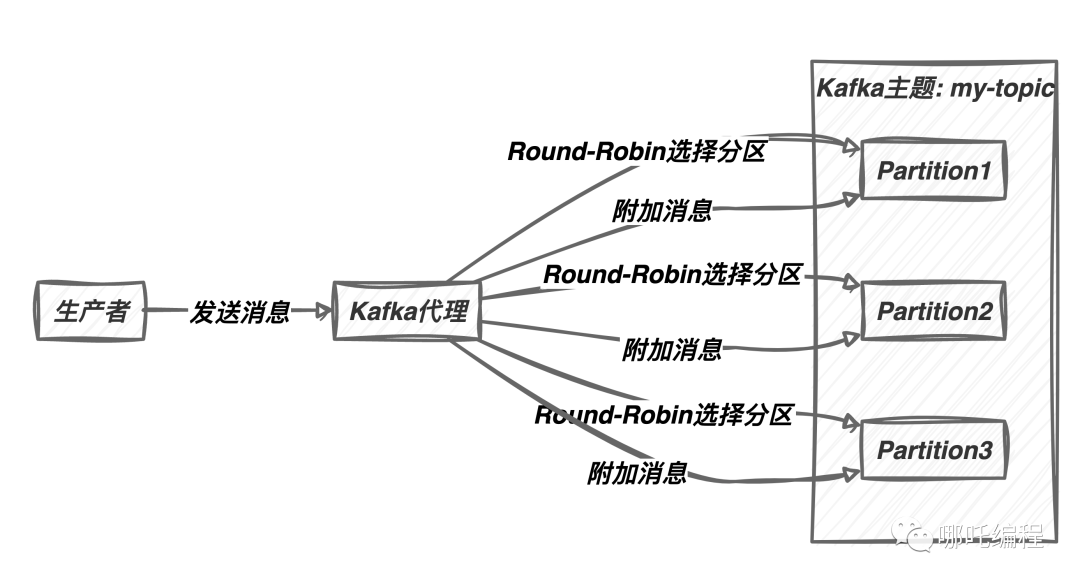
- 生产者发送消息到主题时,不指定目标分区。
- Kafka代理根据Round-Robin算法选择下一个可用分区。
- 消息被附加到选定的分区。
这个策略适用于以下情况:
- 当消息的键没有特定的含义或用途时,Round-Robin是一种简单的分区策略。
- 当你希望均匀地将消息分布到各个分区时,这是一种有效的策略。
这段代码示例展示了如何创建一个使用Round-Robin分区策略的Kafka生产者。以下是代码的详细说明:
导入所需的库:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;关键字:
声明:我公司网站部分信息和资讯来自于网络,若涉及版权相关问题请致电(63937922)或在线提交留言告知,我们会第一时间屏蔽删除。
有价值
0% (0)
无价值
0% (10)
发表评论请先登录后发表评论。愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。
-
TOP